文章目录
- 一、关于 TruLens
- How it works
- 二、安装
- 三、快速使用
- Get DataIn
- Create Vector Store
- Build RAG from scratch
- Set up feedback functions.
- Construct the app
- Run the app
一、关于 TruLens
Evaluate and Track LLM Applications
- 官网:https://www.trulens.org
- github : https://github.com/truera/trulens
- trulens_eval 文档:https://www.trulens.org/trulens_eval/getting_started/
- trulens_explain :https://www.trulens.org/trulens_explain/getting_started/quickstart/
- 社区:https://communityinviter.com/apps/aiqualityforum/josh
- https://colab.research.google.com/drive/1n77IGrPDO2XpeIVo_LQW0gY78enV-tY9
TruLens提供了一套用于开发和监控神经网络的工具,包括大型语言模型。
这包括使用 TruLens Eval 评估LLM 和 基于LLM的应用程序,以及使用 TruLens Explain 评估深度学习可解释性的工具。
TruLens Eval 和 TruLens Explain分别装在单独的包装中,可以单独使用。
不要只是查看你的llm应用程序! 使用TruLens系统地评估和跟踪您的LLM实验。
当您开发应用程序(包括提示、模型、检索器、知识来源等)时,TruLens Eval 是您了解其性能所需的工具。
细粒度、与堆栈无关的检测和全面的评估可以帮助您识别故障模式并系统地迭代以改进应用程序。
TruLens背后的核心概念,包括
- 反馈功能:https://www.trulens.org/trulens_eval/getting_started/core_concepts/
- The RAG Triad:https://www.trulens.org/trulens_eval/getting_started/core_concepts/rag_triad/
- Honest, Harmless and Helpful Evals : https://www.trulens.org/trulens_eval/getting_started/core_concepts/honest_harmless_helpful_evals/
How it works
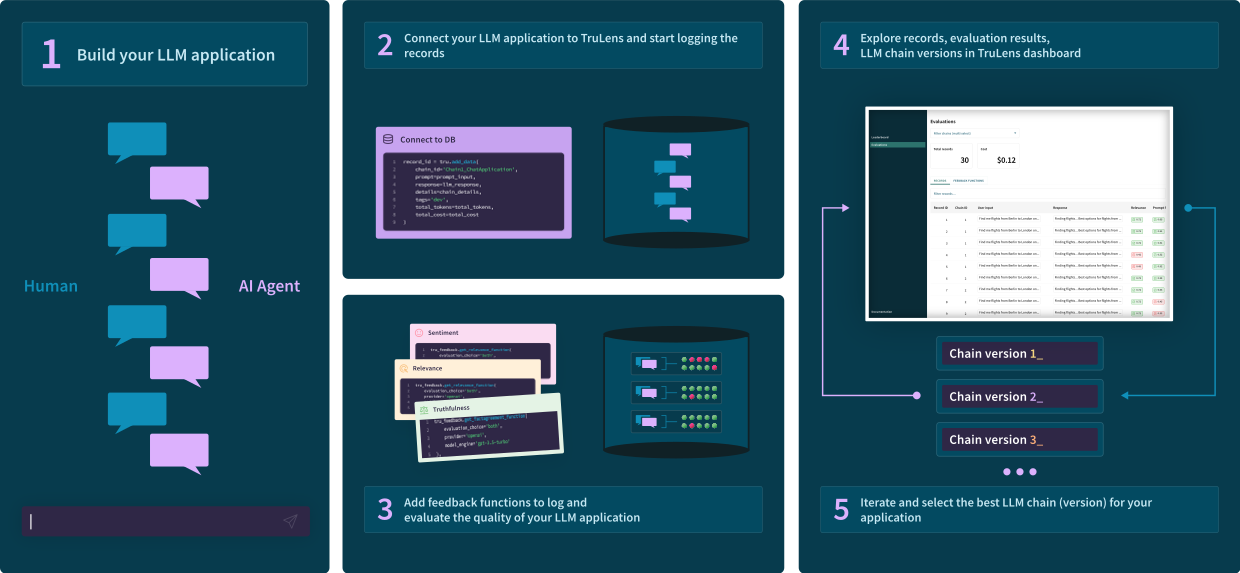
构建您的第一个原型,然后使用TruLens连接仪器和日志记录。
决定你需要什么反馈,并用TruLens指定它们与你的应用程序一起运行。
然后在易于使用的用户界面中迭代和比较应用程序的版本。
二、安装
pip install trulens-eval
使用源码安装
git clone https://github.com/truera/trulens.git
cd trulens/trulens_eval
pip install -e .
三、快速使用
在这个快速入门中,您将从头开始创建一个RAG,并学习如何记录它并获得LLM响应的反馈。
为了进行评估,我们将利用基础性、上下文相关性和答案相关性的“幻觉三元”。
你可以在 colab 中查看:
https://colab.research.google.com/github/truera/trulens/blob/main/trulens_eval/examples/quickstart/quickstart.ipynb
安装依赖
! pip install trulens_eval chromadb openai
import os
os.environ["OPENAI_API_KEY"] = "sk-..."
Get DataIn
this case, we’ll just initialize some simple text in the notebook.
university_info = """
The University of Washington, founded in 1861 in Seattle, is a public research university
with over 45,000 students across three campuses in Seattle, Tacoma, and Bothell.
As the flagship institution of the six public universities in Washington state,
UW encompasses over 500 buildings and 20 million square feet of space,
including one of the largest library systems in the world.
"""
Create Vector Store
Create a chromadb vector store in memory.
from openai import OpenAI
oai_client = OpenAI()
oai_client.embeddings.create(
model="text-embedding-ada-002",
input=university_info
)
import chromadb
from chromadb.utils.embedding_functions import OpenAIEmbeddingFunction
embedding_function = OpenAIEmbeddingFunction(api_key=os.environ.get('OPENAI_API_KEY'),
model_name="text-embedding-ada-002")
chroma_client = chromadb.Client()
vector_store = chroma_client.get_or_create_collection(name="Universities",
embedding_function=embedding_function)
添加 university_info 到嵌入数据库
vector_store.add("uni_info", documents=university_info)
Build RAG from scratch
Build a custom RAG from scratch, and add TruLens custom instrumentation.
from trulens_eval import Tru
from trulens_eval.tru_custom_app import instrument
tru = Tru()
class RAG_from_scratch:
@instrument
def retrieve(self, query: str) -> list:
"""
Retrieve relevant text from vector store.
"""
results = vector_store.query(
query_texts=query,
n_results=2
)
return results['documents'][0]
@instrument
def generate_completion(self, query: str, context_str: list) -> str:
"""
Generate answer from context.
"""
completion = oai_client.chat.completions.create(
model="gpt-3.5-turbo",
temperature=0,
messages=
[
{"role": "user",
"content":
f"We have provided context information below. \n"
f"---------------------\n"
f"{context_str}"
f"\n---------------------\n"
f"Given this information, please answer the question: {query}"
}
]
).choices[0].message.content
return completion
@instrument
def query(self, query: str) -> str:
context_str = self.retrieve(query)
completion = self.generate_completion(query, context_str)
return completion
rag = RAG_from_scratch()
Set up feedback functions.
Here we’ll use groundedness, answer relevance and context relevance to detect hallucination.
from trulens_eval import Feedback, Select
from trulens_eval.feedback import Groundedness
from trulens_eval.feedback.provider.openai import OpenAI
import numpy as np
provider = OpenAI()
grounded = Groundedness(groundedness_provider=provider)
# Define a groundedness feedback function
f_groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons, name = "Groundedness")
.on(Select.RecordCalls.retrieve.rets.collect())
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
# Question/answer
relevance between overall question and answer.
f_answer_relevance = (
Feedback(provider.relevance_with_cot_reasons, name = "Answer Relevance")
.on(Select.RecordCalls.retrieve.args.query)
.on_output()
)
# Question/statement relevance between question and each context chunk.
f_context_relevance = (
Feedback(provider.context_relevance_with_cot_reasons, name = "Context Relevance")
.on(Select.RecordCalls.retrieve.args.query)
.on(Select.RecordCalls.retrieve.rets.collect())
.aggregate(np.mean)
)
Construct the app
Wrap the custom RAG with TruCustomApp, add list of feedbacks for eval
from trulens_eval import TruCustomApp
tru_rag = TruCustomApp(rag,
app_id = 'RAG v1',
feedbacks = [f_groundedness, f_answer_relevance, f_context_relevance])
Run the app
Use tru_rag as a context manager for the custom RAG-from-scratch app.
with tru_rag as recording:
rag.query("When was the University of Washington founded?")
tru.get_leaderboard(app_ids=["RAG v1"])
tru.run_dashboard()
2024-04-28(日)





![[Algorithm][分治 - 归并排序][排序数组][交易逆序对的总数][计算右侧小于当前元素的个数][翻转对]详细讲解](https://img-blog.csdnimg.cn/direct/bacbb81daa8b413c89d8c033026fe962.png)